 Amber
AmberIntroduction
Amber is an open‑source, self‑hosted durable execution runtime for long‑running AI agents.
It lets an agent resume precisely from any completed step when failures occur in production.
As AI agents become longer-running, they need reliability and observability. Once an agent’s work spans hours or days, failures become inevitable. Restarting from the first step can mean repeating expensive agent runs and risks duplicated side effects.
Amber addresses this need by preserving an agent’s progress, resuming its work after a failure, and integrating agent-specific observability.
In this case study, we introduce how durable execution applies to AI agents, compare existing durable execution solutions, and discuss how we addressed agent-specific challenges while building Amber.
Background
Failure in Production
In distributed systems, a process may complete part of its work successfully before a later step crashes. When this happens, the process can be stuck in limbo. There’s no preservation of what already happened or where it’s safe to resume. Restarting from the beginning can cause real consequences, like charging a payment twice.

When systems aren’t distributed, the state at the time of failure can be kept in memory. But when a system is distributed, you need something more than memory to help persist that state.
This is where durable execution comes in.
What is Durable Execution?
Durable execution is built around workflows and steps that allow code to be replayed deterministically after failures.
A workflow wraps the orchestration logic that defines a process. It represents the execution path and ensures the code can resume from where it left off, rather than starting over.

Within a workflow are steps, which wrap operations whose results should be preserved across failures. Steps act as checkpoints in execution. When a step completes, the runtime stores its return value so progress can be recovered later. Steps can wrap operations such as API calls, database writes, or work that would be expensive or unsafe to repeat.

Durable execution persists workflow progress as it runs. If a failure happens, execution resumes from the last completed step instead of starting over. From the developer’s point of view, the application’s execution flow behaves as if the failure had never happened. In other words, durable execution does not make failures happen less; it makes them less consequential.
For example, consider code that executes a sequence of five steps where crashes can happen mid-operation at any step.
Pick a mode, then simulate a crash mid-operation.
Why this Matters for Agents?
Workflows follow a predictable execution path that developers define ahead of time. Agents operate differently.
An agent is an LLM driven system that reasons about a task, takes actions, and adapts based on results until it reaches a goal.

This autonomy is what makes agents suited to more open-ended tasks, in which the exact execution steps cannot be determined in advance. A request like “fix this bug” does not map easily to a predetermined sequence. Instead, an agent decides what actions to take, observes the results, and determines the next step as it works toward a solution.
Agent behavior may be nondeterministic, but its progress can still be preserved through durable steps. Once an LLM call completes, the durable execution engine stores the step’s result so it can be recovered after a failure instead of being re-executed. This allows long-running agents to resume safely without repeating completed work.

This problem is already becoming relevant in practice. Coding agents like Cursor and ChatGPT Codex are already adopting durable execution runtimes or building systems with similar guarantees [2][9].

Challenges with Observability
Agent observability tools provide developers with visibility into agent behavior. They record execution as traces, which are composed of spans representing individual operations such as LLM calls, tool invocations, or database writes.
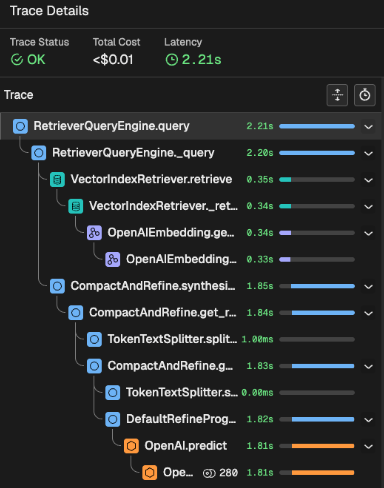
Durable execution platforms record those same operations differently. A workflow step preserves an operation’s result to recover from failures, while a span captures the details of what happened.

Traces matter most after a production failure, which is exactly when durable execution and observability fall out of sync. During recovery, completed steps are restored instead of re-executed. Because spans are only emitted when code runs, restored steps produce no spans. As a result, the resumed run produces an incomplete trace, lacking the spans emitted before the failure.

Developers investigating a failure may only see the newly executed portion of a resumed run, rather than the history leading up to the failure.
Integrating observability with durable execution preserves an agent’s progress and its visibility across failures.
Existing solutions
Choosing a durable execution platform requires weighing three key factors:
- To what degree the runtime is proprietary: some are fully open source, while others let you view the source code but restrict how it can be used, modified, or commercialized.
- Whether you self-host the runtime or consume it as a managed cloud service.
- The infrastructure that each runtime requires to run, ranging from a single process backed by one database to a distributed cluster of services.
The first two matter most to teams with privacy or compliance needs that require execution to stay inside their own systems; the third drives the ongoing cost of running it there.
Three existing solutions we considered were DIY, Temporal, and Inngest.
DIY
DIY suits teams that want full control and accept the implementation burden that comes with it. Handling workflow durability yourself means building the underlying infrastructure from components like stateful job queues, database-backed state machines, and checkpointing logic.
As these systems grow, that infrastructure code becomes increasingly difficult to maintain, test, and keep reliable. They often require more effort to reach the same level of resilience as a purpose‑built platform, and may miss edge cases that dedicated systems already handle.
Temporal
Temporal is a general-purpose workflow engine with multi-language SDKs and a deep feature set, used by many large companies at scale. It is fully open source and can be self-hosted or run as a managed cloud service. Temporal is a proven technology with real world results.
Comparatively, Temporal demands the most significant restructuring of the codebase. Code must be organized around a stricter workflow model involving two layers.
Additionally, running Temporal requires operating a cluster of services, which can be a significant burden for a smaller team to self-host and maintain.
Inngest
Inngest, like Temporal, offers a cloud service that manages durable execution, but it simplifies the developer experience significantly. It also requires less infrastructure to run.
While the source code for Inngest is available, and self-hosting Inngest is possible, the license for the source code is not exactly open source. This lack of clarity may deter developers and organizations who are looking to self-host or have concerns about privacy and data compliance.
While the market for durable execution has several strong solutions, these existing solutions leave a gap in the market. Smaller organizations that want to self-host for cost or compliance reasons do not have a simple solution that combines good developer experience and easy to manage infrastructure.

Amber is fully open source and self-hosted on Amazon Web Services (AWS).
It builds on DBOS, an open-source durable execution engine that runs embedded within the application rather than as a separate service, and relies on Postgres alone for infrastructure.
While Amber does not yet support multiple agent frameworks, it offers native integration with the OpenAI Agents SDK, written in Python. We chose the OpenAI Agents SDK as it’s among the most widely adopted frameworks for building agents.
Amber Walkthrough
Amber fills the gap left by existing durable execution and observability platforms. Current durable execution platforms focus on workflow reliability, while observability tools focus on traces and logs. Amber combines both in a self-hosted solution designed specifically for AI agents.

Amber Overview
Amber ships with a Python SDK and a command-line tool for deploying and managing agents as durable workflows.
Developers can use the CLI to run their durable agents locally during development or deploy them to their own infrastructure when moving to production. From there, workflows can be inspected, debugged, and replayed through a dashboard or directly with Amber’s CLI tool.
SDK
Amber provides a simple Python SDK that serves as the entry point to durable execution. Developers import the Amber library and annotate their agent code to register their agent as a durable workflow. Behind those SDK decorators, Amber handles the work of checkpointing steps, recovering after failure, and integrating traces.
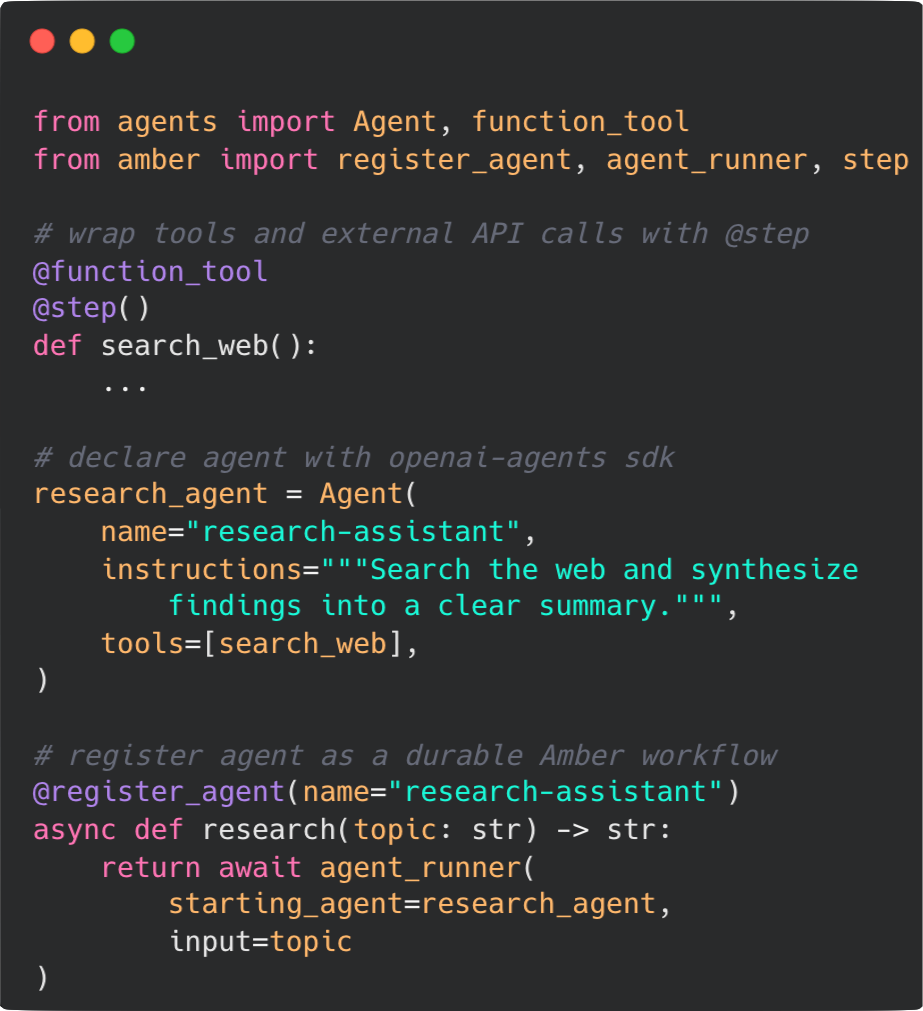
For additional setup instructions and and SDK details see the amber-sdk-README.
Dashboard
Amber provides a dashboard for managing and debugging durable workflows. The dashboard allows for agent-specific tracing by using the OpenAI Agent SDK’s own TracingProcessor API.
Amber Dashboard
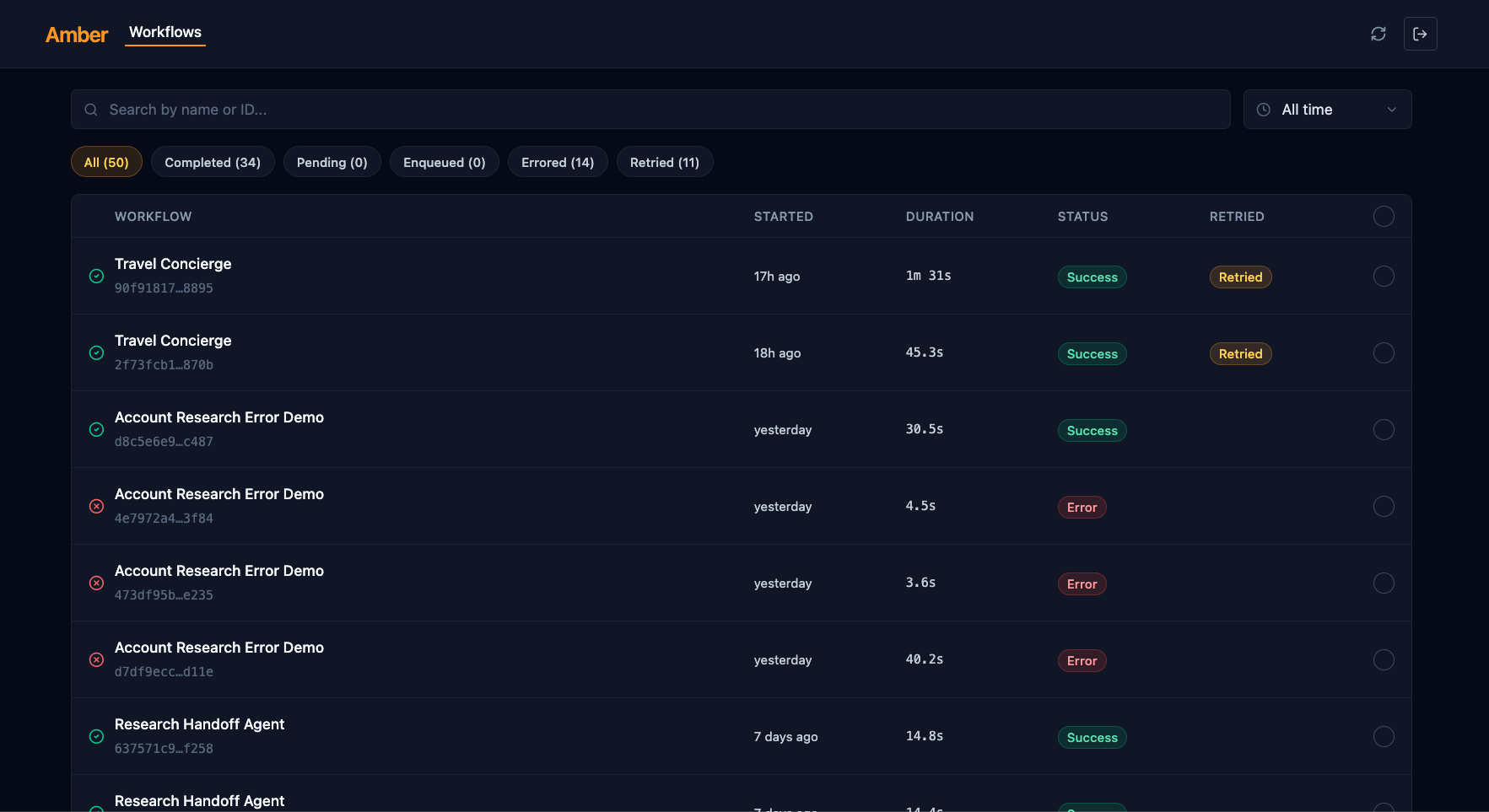
Amber Workflow Page
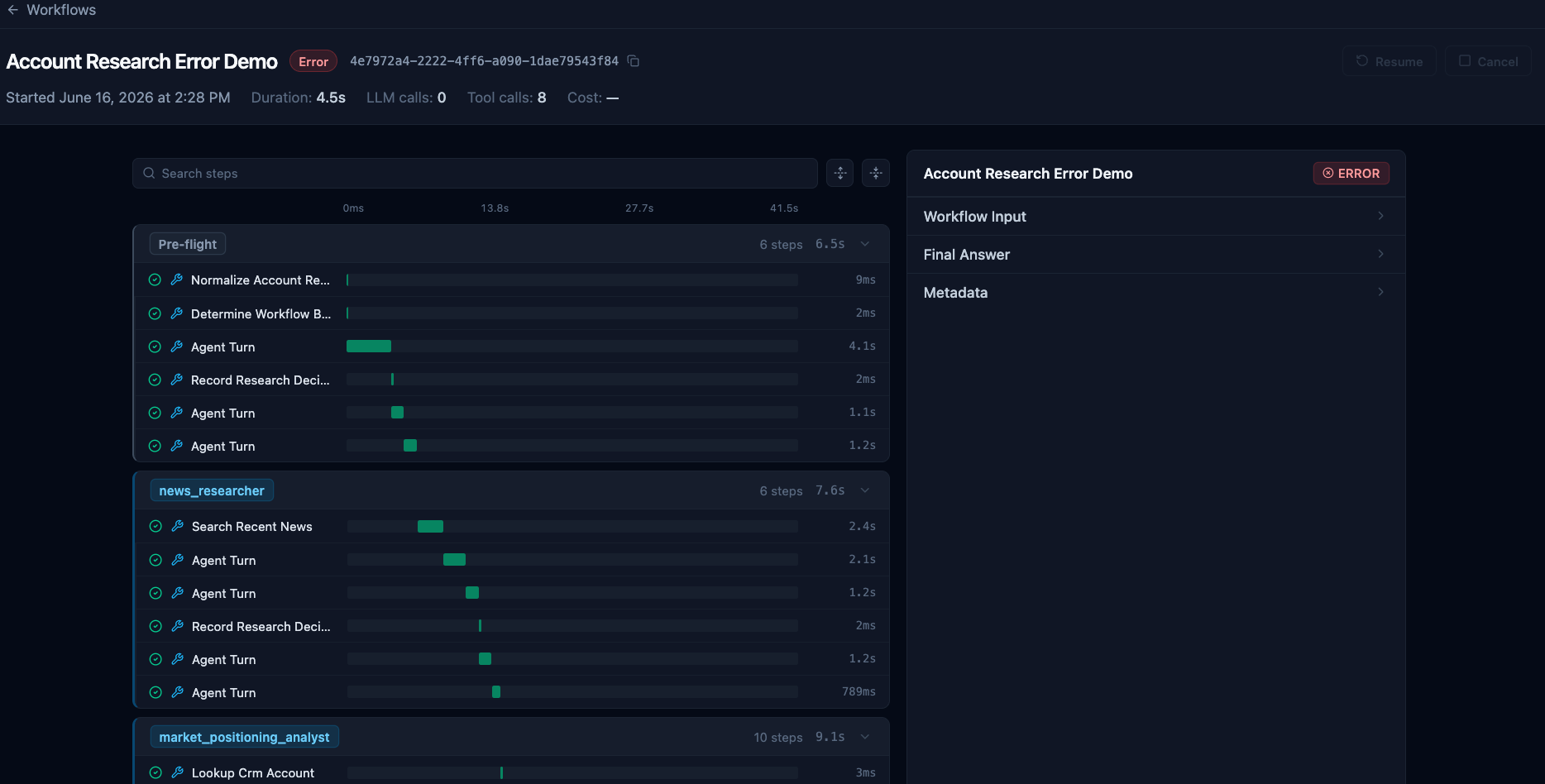
Review Errored Workflow
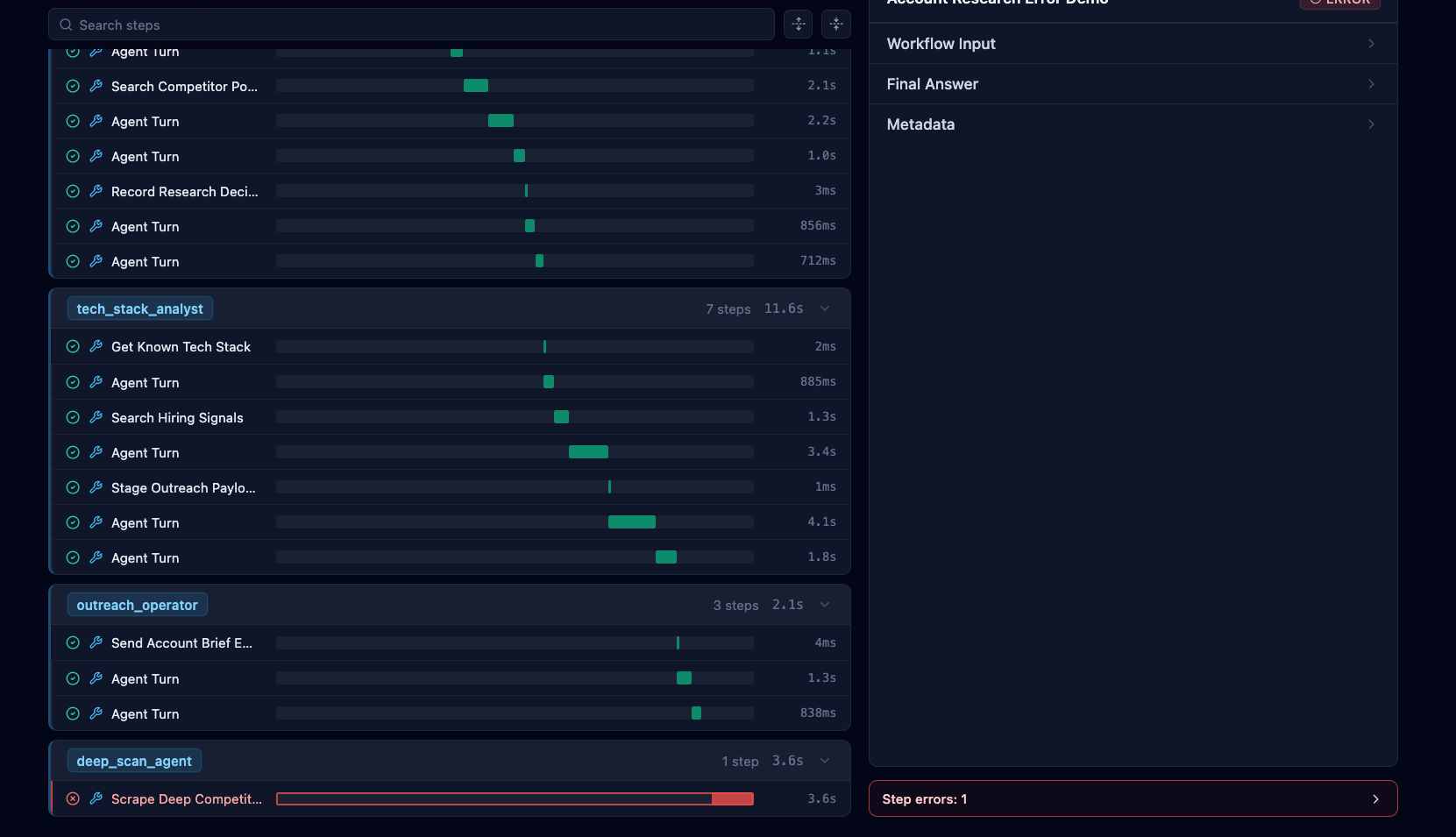
Analyze Workflow Error
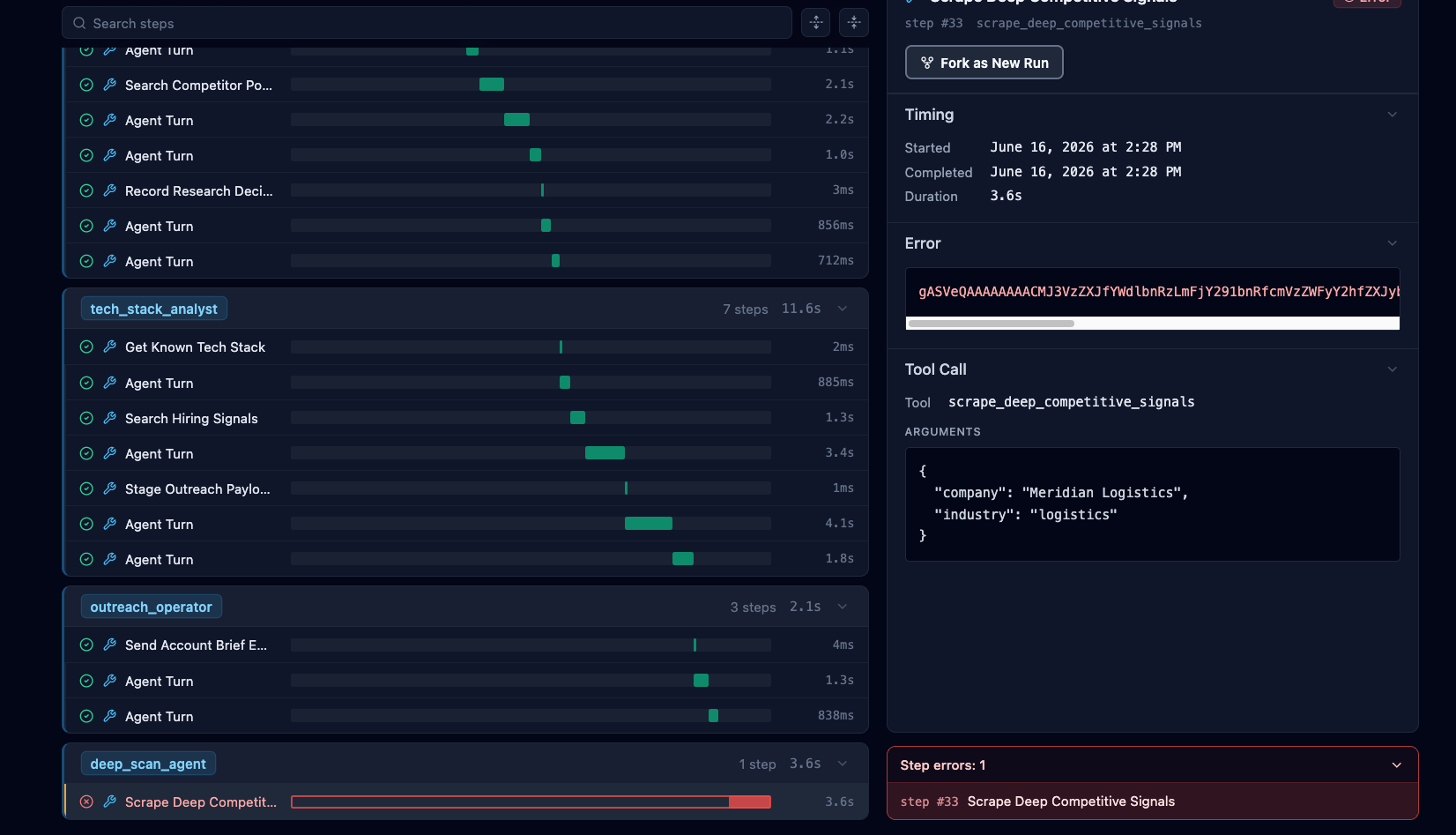
Fork New Workflow
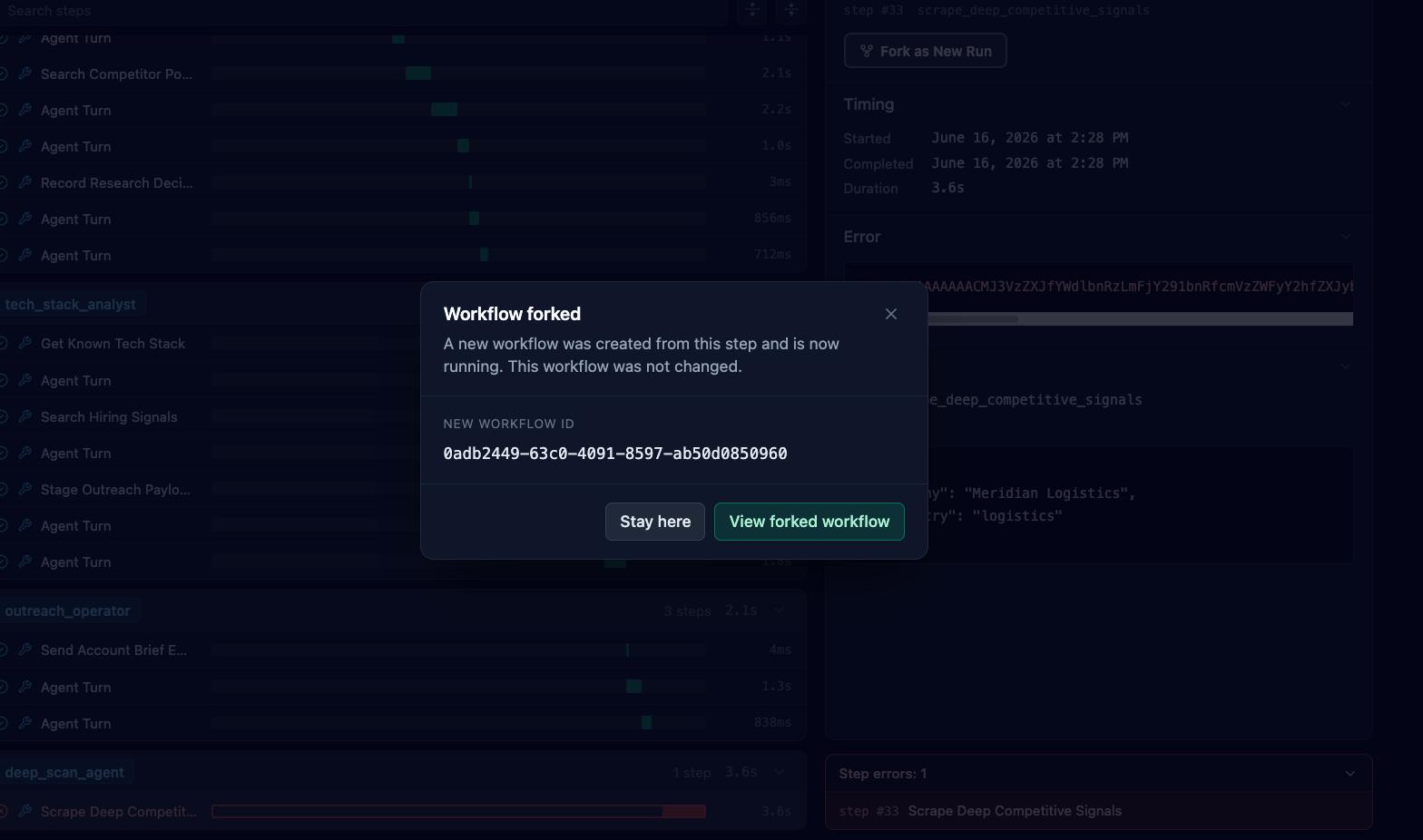
Successful Fix
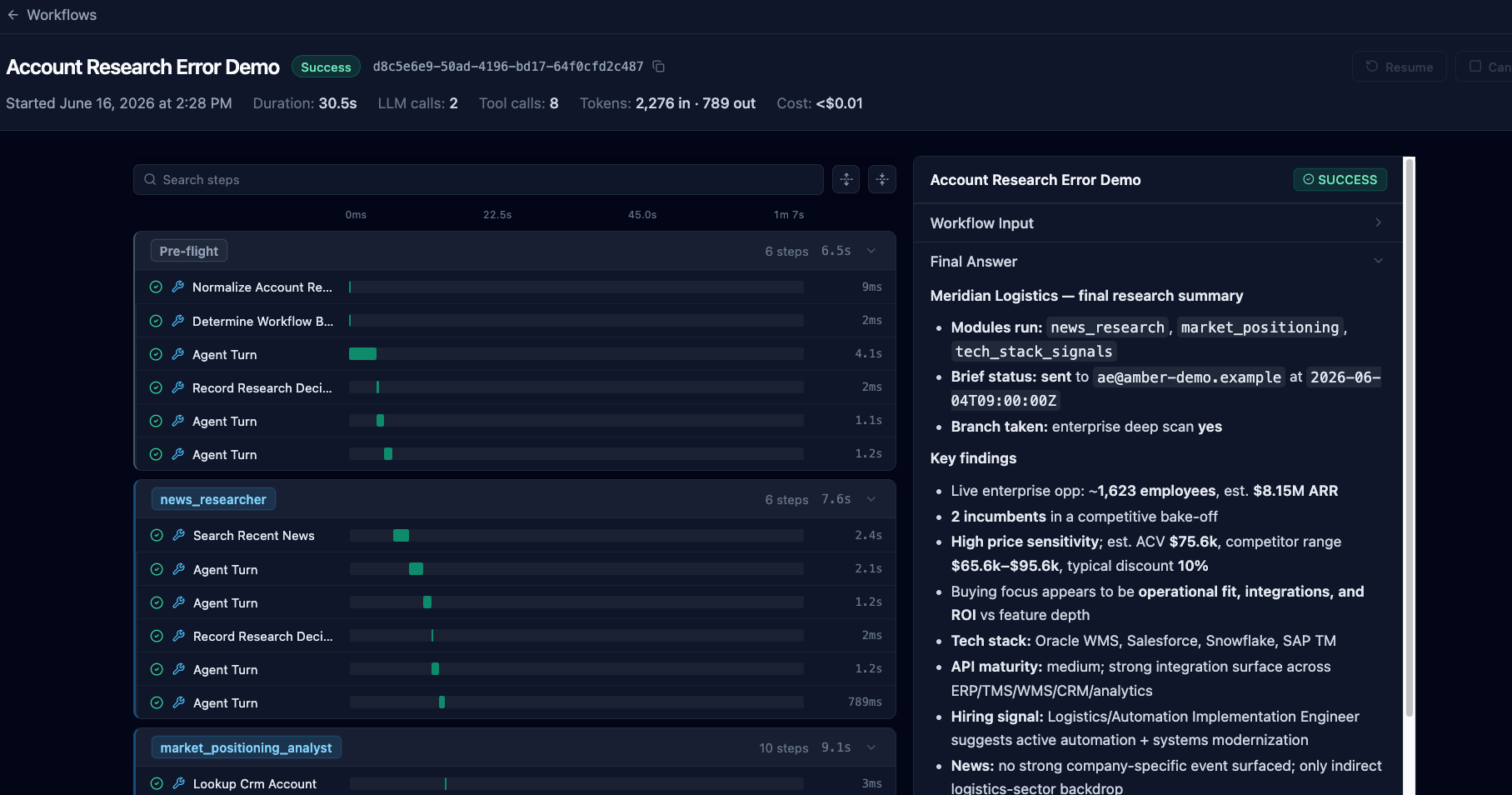
From a failed workflow, developers can inspect completed steps and resume from any previously completed step to replay part of the workflow. This allows developers to investigate failures without rerunning the entire workflow.
Developers can add logs, make code changes, and replay failed sections to understand what went wrong.
CLI
Amber also exposes the dashboard’s API through the CLI tool.
Agents in Amber CLI
Inspect Workflows

Debug Workflow State
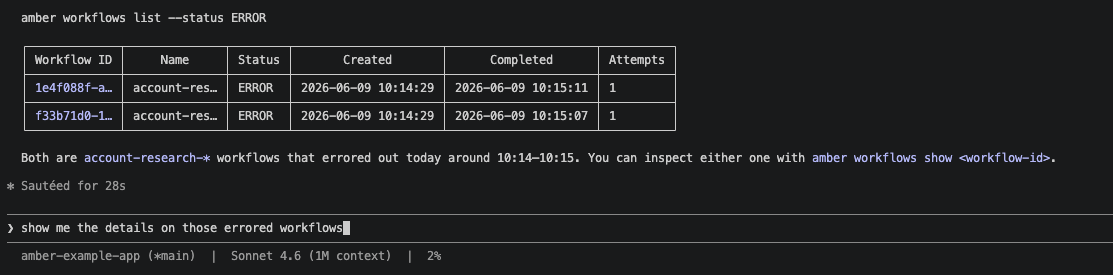
Review Workflow Information
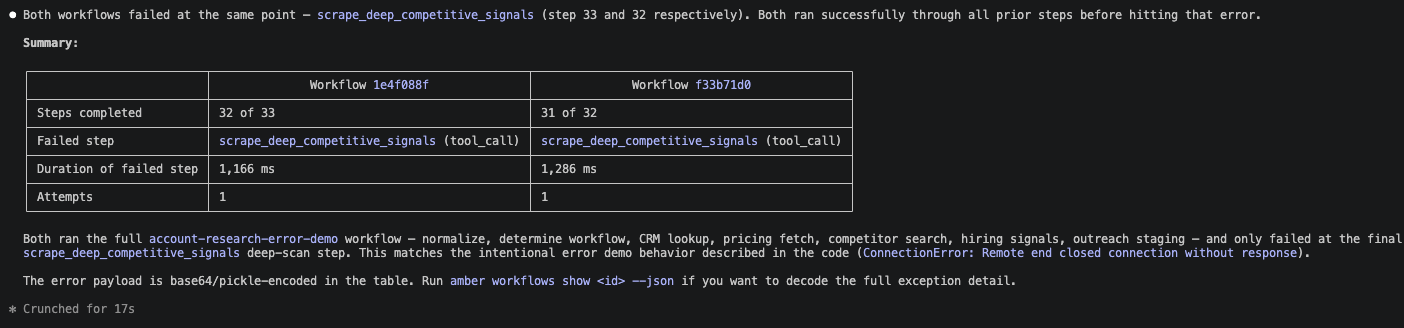
This allows the developers to manage and debug their agent workflows directly from the terminal. They can even direct a coding agent to query agent workflows and debug on their behalf.
How we built Amber
High-Level Architecture
To better understand how we built and deployed Amber, let’s look at a high level overview of the components.

Amber’s architecture is composed of the following layers:
- Web layer, which routes traffic and hosts the Dashboard frontend and any optional Agent frontends.
- Server layer, which hosts the Agents built with our SDK. In addition to hosting the Agents, this layer is also home to the Dashboard backend and worker pool.
- Database layer, where Agent execution steps are queued and the results stored.
The first component we will discuss is the durable execution engine itself, which is part of the server layer.
Durable Execution Engine

Early in Amber’s design, we debated whether to build our own durable execution system or adopt an existing solution.
We ended up selecting DBOS because it aligned with Amber’s goal of keeping the architecture simple. DBOS runs directly inside the developer’s application and only requires a Postgres database for durability. Instead of relying on a separate queueing system, DBOS uses Postgres itself to persist and schedule workflow execution.
Workflow state, queueing, and observability data could all live in one place. This simplified Amber’s architecture and reduced the infrastructure developers needed to manage.

Worker Runtime
Originally, Amber supported both immediate and queued workflow execution. However, requiring developers to choose between execution models added unnecessary complexity. Since Amber primarily targets long running agent workflows that may pause, fail, or resume, we standardized on queued execution.
As a result, Amber separates request handling from long-running agent execution. The developer’s application service running in AWS ECS accepts requests and enqueues agent workflows in Postgres. A dedicated worker service in AWS ECS then drains the queue and performs the long running work. This removes the need for a separate queueing system like AWS SQS.
This separation allows the application service and worker runtime to scale independently based on their own traffic patterns.

At this point, Amber could define durable agent workflows and execute them reliably. The next challenge was deployment. Since Amber is self-hosted, developers needed a way to run these components inside their own AWS account.
To make the AWS architecture easier to understand, we break it down into its major components before showing how everything fits together.
Self-hosted AWS Deployment
To simplify deployment, we built the Amber CLI to provision the required infrastructure and deploy the application runtime in a couple of commands.
The major deployment pieces are CloudFront (AWS’s Content delivery and routing), ECS Fargate (AWS’s serverless container runtime), RDS (AWS’s managed relational database service), and supporting AWS services.
CloudFront
CloudFront routes traffic by path:
- Application API requests go to the developer's FastAPI service.
- Dashboard UI requests go to the Amber Dashboard frontend written in React.
- Dashboard API requests go to a separate FastAPI service and require Cognito authentication.
- If the developer's application includes a React frontend, CloudFront serves that frontend at
/and routes the FastAPI service under/api/*.
The dashboard frontend loads in the browser and then uses Cognito sign in before requesting workflow data from the dashboard API.

ECS Fargate and RDS
Amber deploys three main ECS Fargate services, which are containerized applications that run without requiring developers to manage severs:
- Developer's application FastAPI service which handles API requests and enqueues agent workflows.
- Developer's worker service which drains queued workflows and executes long-running agent workflows.
- Admin Dashboard API service which reads workflow state and displays the information to the dashboard UI.
All three services connect through RDS Proxy to RDS Postgres, a managed PostgreSQL database. Postgres stores the durable workflow state, queue state, step history, and agent event data used by Amber.

Supporting AWS Services
List of supporting AWS services:
- ECR stores the developer's application, worker, and dashboard API container images.
- SSM Parameter Store stores OpenAI API key.
- Secrets Manager stores the database connection URL and RDS Proxy credentials.
- S3 serves the static frontend assets for the Amber admin dashboard and, if configured, the developer's React frontend.
- Cognito manages authentication for the admin dashboard.
- CloudWatch collects service logs and queue metrics for ECS autoscaling.

Full AWS Diagram of Amber

Engineering Tradeoffs and Challenges
Durable Execution Engine

The two main options we considered were AWS Durable Lambdas and DBOS Transact. Since Amber’s infrastructure already relied on AWS services, AWS Durable Lambdas seemed like a natural fit. Durable Lambdas support long-running workflows without the 15 minute limit of standard AWS Lambda functions, which made them an attractive option.
Although AWS Durable Lambdas met many of Amber’s technical needs, we found that DBOS fit Amber’s architecture better. Amber was designed around an embedded SDK model where developers add durable execution into their existing applications through decorators. DBOS runs inside the developer’s application and only requires a Postgres database to provide durability, queue workflows, and store agent-specific traces.
With AWS Durable Lambdas, we would need more AWS services to accomplish the same thing. To support asynchronous execution, we would likely introduce services such as SQS or EventBridge to decouple request handling from workflow execution. For agent traces, a separate data store is needed to store that information because workflow checkpointing is abstracted behind AWS managed orchestration.
Tradeoffs
The main tradeoff of using DBOS is that queueing, durability, and agent trace storage are all consolidated into Postgres. Although DBOS can sustain over 40,000 workflow or step executions per second on a single database, the database remains a central dependency. Under heavy workloads, developers must monitor performance, connection limits, and worker concurrency more carefully. Scaling beyond a single database is possible through workflow sharding, but at the cost of additional operational complexity.
We accepted this tradeoff because it aligned with Amber’s goal of being a lightweight, self-hosted durable execution platform with minimal infrastructure while still providing rich agent observability.
Agent Tracing and Observability

One challenge in Amber was collecting agent traces and mapping each span correctly to its durable step. While DBOS provides workflow data, it does not capture agent-specific data such as LLM calls, tool invocations, or agent handoffs. Since Amber focuses on long-running AI agents, developers need visibility into both.
We first collected traces using an open-source observability platform, Arize Phoenix, with minimal implementation. The platform automatically captured traces using an instrumentation library, OpenInference. However, one problem was that the platform’s data was not linked with DBOS’s data. As a result, resumed workflows were disconnected from the platform’s observability data.
We dropped the platform but kept the instrumentation library to customize ourselves. While the library collected traces automatically, we stamped each span with its DBOS workflow ID. That tied every span to the step that produced it.
The library stored traces in a nested tree that captured which agent made each tool call and where subagents were handed off from. To pull them out, we wrote custom query logic that was tedious to maintain. To reduce code complexity, we switched our trace collection source directly to the OpenAI Agents SDK’s TracingProcessor API. As a result, we did not need to write custom query logic to get the agent relationship data anymore.
Tradeoffs
The main tradeoff is that Amber’s tracing is more tightly coupled to the OpenAI Agents SDK, making support for other frameworks more limited. We accepted this tradeoff because it simplified our codebase, removed an unnecessary dependency, and provided cleaner agent-specific observability within Amber’s dashboard.
Embedded SDK Architecture vs Separate Runtime Server

Our initial product decision was to have the developers host their agents on a runtime server that Amber would provide. The goal was to abstract away the durable execution runtime and manage it on the developer’s behalf. However, this would require them to shape their application around our runtime, which created unnecessary friction.
Another observation we made was that the runtime server’s main responsibility was only initializing the durable execution engine on behalf of the developer. Continuing with a separate runtime server meant introducing another network hop for developers who had their own application. Their application would first need to communicate with our runtime server to start a workflow.
As a result, we decided to remove the separate runtime server because it did not provide meaningful value to the developers. Since Amber is designed to support self-hosting, eliminating the runtime server also reduced infrastructure overhead by removing the need for an extra AWS ECS service.
We then simplified the SDK and made it easier for the developer to embed into their application. Instead of architecting their application around Amber, developers only need to import the SDK and decorate the functions or agents they want durable execution applied to.
Tradeoffs
One tradeoff of the embedded SDK approach is that the developer’s application becomes tightly coupled to the durable execution runtime. If the developer’s application goes down, workflow execution pauses until it becomes available again.
We accepted this tradeoff because developers no longer need to provision and manage a separate runtime server.
Future Work
Versioning
Currently, Amber does not handle versioning when the developers update their code while there are still pending or enqueued workflows. As a result, workflows left in the queue after a deployment will execute using the updated codebase rather than the version they were originally created with. This can create compatibility issues between releases of the developer’s application.
As an intermediate solution, Amber allows developers to manually remove pending or enqueued workflows before deploying new code. However, this is a destructive action and cannot be reversed, so developers must use it with caution.
In future releases, Amber will support workflow versioning. Older workflows will continue to be executed against the code version they were created with, while newly created workflows will run using the updated codebase. This will allow deployments to be safer and reduce the risk of workflow failures caused by incompatible code changes.
Better Support for Agents
Amber currently provides limited controls for how agents retrieve workflow information through the CLI. While agents can query workflows via the CLI command workflows, agents will not always adhere to using that path when trying to get workflow information. In some cases, this can result in agents attempting to directly access your database to retrieve workflow data.
In the future, Amber will introduce dedicated skill files to better constrain agent behavior and guide agents toward approved methods to retrieve workflow data. Amber will also expose workflow information through an MCP server, giving agents a standardized interface for querying workflow state and metadata. Together, these additions will improve the user experience and reduce the risk of unintended actions when agents retrieve workflow information.
Support for Other Agent Frameworks
Amber only supports the OpenAI Agents SDK. This decision allowed us to focus on building Amber and not managing the additional complexity of adding different agent frameworks.
In the future, we plan to expand support for additional agent frameworks. This will give developers more flexibility in how they build their agents and allow Amber to be framework agnostic.
References
- https://temporal.io/blog/what-is-durable-execution
- https://cursor.com/blog/cloud-agent-lessons
- https://docs.aws.amazon.com/lambda/latest/dg/durable-basic-concepts.html
- https://temporal.io/blog/of-course-you-can-build-dynamic-ai-agents-with-temporal
- https://www.dbos.dev/blog/why-postgres-durable-execution
- https://docs.dbos.dev/architecture
- https://temporal.io/
- https://www.inngest.com/docs/learn/how-functions-are-executed
- https://temporal.io/blog/improving-java-sdk-codex-openai